
- Zur Anmeldeseite (ausgebucht)
- Ablauf Open Data Day München 2023 (PDF)
- #oddmuc
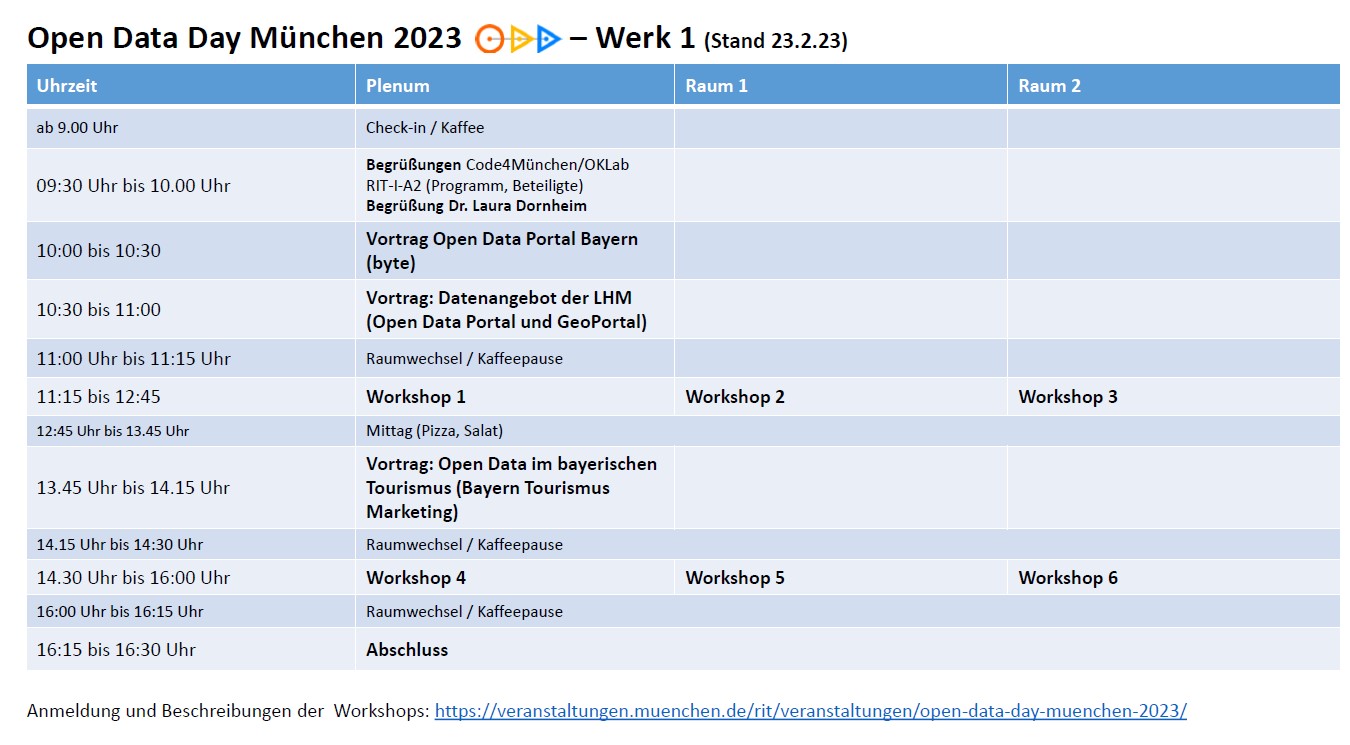
Die Aufteilung der Workshops auf Räume erfolgt am Beginn der Veranstaltung.
Vorträge
- Eine Open Data Plattform für Bayern (10.00 – 10.30 Uhr)
Die Bayerische Agentur für Digitales ‘byte’ arbeitet an einer Open Data Plattform für den Freistaat Bayern. Dabei wollen wir auch die Community miteinbeziehen! Auf dem Open Data Day in München stellen wir das Projekt vor und geben Einblicke in unsere Pläne. (Dr. Christian Bemmerl und Luis Moßburger, byte) - Open Data Portal und GeoPortal der Landeshauptstadt München (10.30 – 11.00 Uhr)
Was bieten die beiden städtischen Datenportale? Wie kann man sie nutzen?
(Frank Börger, IT-Referat und Bernhard Jackl, Kommunalreferat GeodatenService) - Open Data im bayerischen Tourismus (13.45 – 14.15 Uhr)
Im Vortrag wird es einen Einblick in die Entwicklungen hin zu Open Data im bayerischen Tourismus geben. Dabei werden Strategien, Herausforderungen und technische Infrastruktur näher beleuchtet und der aktuelle Stand der Dinge vorgestellt. (Markus Garnitz, Bayern Tourismus Marketing GmbH)
Workshops
Die Aufteilung der Workshops auf Räume erfolgt am Beginn der Veranstaltung.
Vormittags (11.15 – 12.45 Uhr)
- Überholabstände messen mit dem OpenBikeSensor – Potenzial und Herausforderungen offener Daten:
Geringe Seitenabstände von vorbeifahrenden Fahrzeugen sind für Radfahrende stressig und führen immer wieder zu Beinahe-Unfällen, aber auch zu schweren Unfällen. Sie halten Menschen davon ab, auf bestimmten Strecken oder generell mit dem Fahrrad zu fahren.
Im Projekt “Überholabstände messen mit dem OpenBikeSensor” erhebt der Allgemeine Deutsche Fahrrad-Club e.V. (ADFC) München die tatsächlichen Seitenabstände mithilfe kleiner, an Fahrrädern montierten OpenBikeSensoren: Ultraschall-Abstandsmessungen nach links und rechts werden dazu mit GPS-Koordinaten und Uhrzeit verknüpft. Die Daten werden zusammengeführt und auf einer Karte visualisiert.
Im Workshop diskutieren wir die Problemstellung, die Hintergründe und werfen einen ersten Blick auf die Potentiale und Auswertungsmöglichkeiten der erhobenen Seitenabstands-Daten, die nach Abschluss der ersten Erhebungsphase als Open Data veröffentlicht werden sollen. (Johan Buchholz, ADFC) - Einführung in Machine Learning und Deep Learning:
Was genau ist Machine Learning eigentlich? Was sind Neuronale Netze, Supervised und Unsupervised Learning, und welche ethischen Fragen sind im Bereich der künstlichen Intelligenz zu beachten? Diese Fragen werden wir im Workshop diskutieren und unser erstes kleines Machine-Learning-Modell bauen. Programmierkenntnisse sind nicht erforderlich. (Pia Baronetzky, Florian Edenhofner, Daniel Manny, CorrelAid) - Datenspende – Ergänzung oder Konkurrenz zu Open Data?
Datenspende – Euer Input ist gefragt! Gemeinsam mit der Münchner Open Data Community wollen wir konkrete Anwendungsfälle für das freiwillige Spenden von Daten an die Münchner Stadtverwaltung suchen.
Unter welchen Bedingungen sind Bürger*innen bereit, freiwillig Daten zu sammeln und an die Verwaltung zu spenden? Wann ist die Datenspende angemessen und wo beginnt schon Clickworking, für das eine Vergütung erwartet wird? Welche Arten von Daten können und wollen Bürger*innen sammeln und spenden – von Umweltdaten, über Mobilitäts- bis hin zu hochpersönlichen Gesundheitdaten?
Euer Input ist gefragt und fließt unmittelbar in die Daten-Sourcing-Strategie des InnovationLabs der IT der Landeshauptstadt ein. (Fabian Kors, InnoLab/IT-Referat)
Nachmittags (14.30 – 16.00 Uhr)
- Open Data mit Shiny – Mehrwerte aus Daten schaffen:
In dem Workshop soll es darum gehen, wie Open Data durch den Einsatz von Datenvisualisierung bereichert werden kann. Dies soll anhand einer Shiny App zu Fahrraddaten der LHM erläutert werden. R Shiny ist ein R-Paket mit welchem interaktive Web-Applikationen erstellt werden können. Der Fokus des Workshops soll darauf liegen, in die grundlegende Syntax von Shiny Apps einzuführen und Möglichkeiten darzulegen, wie ein gelungener Workflow zu strukturieren ist. (Txomin Basterra Chang, CGI/IT-Referat) - Mit Open Data zur KI – Merkmale und Trainingsdaten aus offenen Daten generieren:
Im Workshop versuchen wir gemeinsam aus frei verfügbaren Informationen geeignete Trainingsdaten zum maschinellen Lernen zu generieren.
Hierbei betrachten wir 3 Aspekte: Wie man existierende Datensätze findet und transformiert, wie man Geo-Locations als zusätzliche Merkmale nutzen kann, und wie man Bild-Datensätze mithilfe von öffentlichen Markierungen generiert.
Der Workshop beinhaltet praktische Abschnitte, die Mithilfe von Python in Jupyter Notebooks bearbeitet werden; eine geeignete Entwicklungsumgebung kann in wenigen Minuten selbst aufgesetzt werden. (Fabian Reinold, InnoLab/IT-Referat) - City API – Einführung in API Gateways oder ‘Wie baut man einen Knowledge Graph’:
Im Workshop wird erklärt wen man verschiedene APIs (wie z.B. Wikidata, OpenStreetMap, CKAN und Datenquellen) in einer GraphQL API Gateway zusammenführt. Vorbereitung: Am besten schon mal VSCode, Git und NodeJS/Typescript auf dem eigenen Rechner installieren und https://github.com/saerdnaer/city-api auschecken. (Andreas Hubel, OK Lab)